Hyperparameter search using Bayesian Optimization and an Evolutionary Algorithm
This blog will briefly describe the need for hyperparameters in the machine learning algorithm, whether it is a statistical method or a very complex deep neural network architecture. Also, I’ll compare and analyze the two hyperparameter search techniques: Bayesian Optimization and Genetic Algorithm(Evolutionary Algorithm). Finally, I’ll implement these two search techniques in two settings: a statistical machine learning algorithm and a deep neural network architecture and analyze their performance based on the time complexity, search space exploration, memory requirements, and parallelism capabilities.
INTRODUCTION
Machine learning algorithms can solve a fundamental problem and also a complex problem. Machine learning models can learn by themselves using the training data and perform their predictions on the test data based on the learning. Based on the problem, we can select which machine learning model to use. For any machine learning model, its performance depends on learning.

In any machine learning model, its hyperparameters are a significant component in the learning cycle. Unfortunately, the tuning of hyperparameters requires a lot of expertise, and it is not a trivial task.
Motivation for hyperparameter search: While creating a machine learning model, we have a lot of design choices for our model architecture, and initially, we don’t know which set of design choices will be optimal for our model architecture. The model architecture consists of many parameters, and there are two types of parameters: model parameters and hyperparameters. The model parameters are learned during the training of the model. For example, in a neural network, the layers are associated with the weights and biases, and these weights are updated using backpropagation. Hyperparameters are the parameters that cannot be learned during the training because we need to decide them before the training, and once they are decided, then only training can start. For example, we need to decide the hidden layers, hidden units per layer, activation functions, etc. Given that there are various choices available for these hyperparameters, ranging over each possibility is not possible, and that’s why tuning these hyperparameters is very difficult. We use the automated hyperparameter searching techniques, which we will now discuss.

Most people who don’t know these hyperparameter techniques use the trial and error technique and hope that their model will perform better. Instead of doing this, we should use the automated hyperparameter search techniques which we discuss now.
Basic hyperparameter search techniques
- Grid Search: In this technique, we will define the values for all the hyperparameters such that it creates a grid of d dimensions where each of these dimensions denotes a hyperparameter. The model will train each combination to present in the grid and take that combination that gives the best result.
- Random Search: Random search works the same as the grid search except that it randomly picks the points from the configuration space we defined for the hyperparameters.
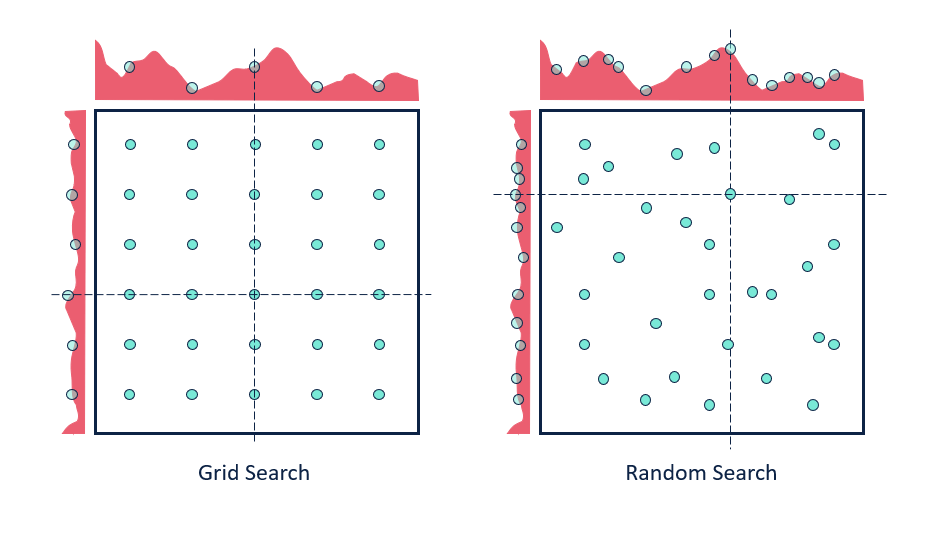
Problems with these basic techniques:
- When the number of hyperparameters in a model is increased, then the configuration space becomes large. As a result, training the model on the various combinations of hyperparameters becomes intractable and not feasible.
- A model's training on one set of hyperparameters is performed in isolation with the other set of hyperparameters. Because of that, these technique does not learn anything from the previous experiments.
- These techniques require a lot of computational resources as well as time. Even then, it is not sure whether they give the best set of hyperparameters or not.
Now it’s time to introduce the hyperparameter search techniques which try to solve the above problems.
Bayesian Optimization
Bayesian Optimization is a hyperparameter search technique that uses the concept of Bayes theorem to guide the search to minimize or maximize an objective function f. This technique creates a probabilistic model, which is also known as the surrogate model and tries to mimic the objective function. After every experiment, the surrogate model learns and becomes more confident that wherein the configuration space, the next set of hyperparameters should experiment, which gives the better performance. There are two major components in this technique: surrogate model, acquisition function.
Gaussian Process: It acts as the surrogate model that tries to learn the relation between the measurement of interest and the configuration space. Gaussian Process uses the prior distribution on the objective function and gives the earlier dissemination on the capacities. For example, there are d hyperparameters; the Gaussian process will induce a multivariate normal distribution. It provides the mean and variance of the prior distribution of the objective function as a range of uncertainty and is determined by the mean and a positive covariance function.
Acquisition Function: It is used to select the next set of hyperparameters on which the model is trained. The acquisition function uses information generated by the gaussian process to select the next sample. Then, it calculates the posterior over the objective functions by adding the generated data generated by the gaussian process. Thus, the posterior is regularly updated once the additional samples and their evaluations are done.
Genetic Algorithm: Evolutionary Algorithm
Evolutionary Algorithm based on the natural concepts of biological evolution. They consider a set of possible candidate solutions or a population that evolves and gives a better result. Evolutionary Algorithms are also known as a population-based optimization algorithm. The Genetic algorithm is well known evolutionary algorithm. It assumes each candidate solution as a chromosome, and in each chromosome, the genes denote the hyperparameters. So the number of genes in each chromosome denotes the number of hyperparameters in the model. Initially, the genetic algorithm will choose some set of chromosomes randomly from the predefined configuration space. Then the model is evaluated on these candidates, and some of the best chromosomes will be selected based on the predefined fitness function. Finally, these chromosomes will be mutated and crossover to generate the new population and this evolution continues till the best solution is not found, or the resources are not exhausted.
Mutation: Genetic Algorithm consists of genetic operators, and mutation is one of them. There are some chromosomes in a generation; then, during the evolution of this generation, mutation operation will alter the values of some of the genes in the chromosome. Thus, a mutation operation is performed to maintain the diversity in the chromosomes from one generation to the next. Modification in the value of the genes depends on the predefined mutation probability. Therefore, the mutation probability should be set low; otherwise, the modifications in the value of the gene will be too much that it will act as a random search.
Crossover: It is also a genetic operator used to generate new offsprings by crossing over the chromosomes of the previous generation. It is used to generate the new population by using genetic values. Crossover operation is also known as recombination. All the chromosomes which are generated by the crossover are subjected to the mutation. Some of the techniques for crossover are as follows:
- Single point crossover: A single point is chosen uniformly in two chromosomes, and then either the values of the right or left part of the chromosomes are swapped.
- Double point crossover: Two points are chosen uniformly, and the values in between these points are swapped.
- Uniform crossover: To make a new offspring, for each value of the gene in the new offspring, one of the values from both the parent chromosomes is chosen uniformly.
Implementation
I have implemented Bayesian Optimization and Genetic Algorithm in two settings: a statistical machine learning algorithm and a deep neural network architecture. I have used Random Forest Classifier as the statistical machine learning algorithm and a deep feed-forward neural network architecture. Both the models are used for the classification task. For this task, I have used the MNIST datasets.
Method Description:
For both the machine learning model, I have selected a set of hyperparameters on which I need to train my model. Initially, I have selected the values of the hyperparameters by myself and trained both the models. Then, I defined the search space for the searching techniques for both models. Both the searching techniques provide a set of hyperparameters that are best possible in the metric of interest. With the provided set of hyperparameters, I have again trained the models and measured their performance. Finally, I have compared and analyzed both searching techniques based on their performance on the models. For example, the hyperparameters that I have decided for the Random Forest Classifier are the number of trees in the forest, maximum depth of any tree, the minimum number of samples to split a node in a tree, the minimum number of samples to be a leaf node, a criterion to measure the quality of a split and the maximum number of features which is to be considered during the split. Similarly, for the deep neural network, the hyperparameters are the number of hidden layers, hidden units per layer, activation functions, optimization function, batch size, number of epochs, and learning rate.
Tools used:
- To implement the Random Forest Classifier model, I have used the sklearn.ensemble.RandomForestClassifier method.
- I have used the hyperopt library for implementing Bayesian Optimization for Random Forest Classifier and hyperas for the deep neural network. In addition, I have used the tpe.suggest algorithm, which acts as a surrogate model for the optimization.
- To implement the genetic algorithm. I have used the TPOT library, where the tpot classifier is used for applying the genetic algorithm on the machine learning model.
Random Forest Classifier using hyperparameter search techniques:
Bayesian Optimization:
Defining the search space
search_space = {'criterion': hp.choice('criterion', c ),
'max_depth': hp.choice('max_depth',d),
'max_features': hp.choice('max_features', f),
'min_samples_leaf': hp.uniform('min_samples_leaf', 0, 0.5),
'min_samples_split' : hp.uniform ('min_samples_split', 0, 1),
'n_estimators' : hp.choice('n_estimators', n)
}Defining the objective function
def Optimization(search_space):estimators = search_space['n_estimators']
criterion = search_space['criterion']
depth = search_space['max_depth']
features = search_space['max_features']
leaf = search_space['min_samples_leaf']
split = search_space['min_samples_split']rfc_model = RandomForestClassifier(criterion = criterion, max_depth=depth, max_features = features,min_samples_leaf = leaf, min_samples_split = split, n_estimators = estimators,
)
accuracy = cross_val_score(rfc_model, x_train, y_train, cv = 5).mean()return {'loss': -accuracy, 'status': STATUS_OK }
Calculating the best possible hyperparameters using fmin from hyperopt
hyperparameters = fmin(fn=Optimization, space=search_space,
algo=tpe.suggest, max_evals = 100,
trials= Trials())Genetic Algorithm:
Defining the search space
search_space = {'n_estimators': n_estimators,'criterion': criterion,
'max_features': features,'max_depth': depth,
'min_samples_split': split,
'min_samples_leaf': leaf
}Using TPOT classifier, implementing the genetic algorithm in Random Forest Classifier
rfc_tpot = TPOTClassifier(generations= 10, population_size= 24,
offspring_size= 12, verbosity= 2, early_stop= 12,
config_dict={'sklearn.ensemble.RandomForestClassifier':
search_space},cv = 5, scoring = 'accuracy'
)A deep neural network architecture using hyperparameter search techniques
Bayesian Optimization
Defining the search space
space = {'Dense1': hp.choice('Dense1', hidden_units ),
'Dense2': hp.choice('Dense2', hidden_units ),
'Dense3': hp.choice('Dense3', hidden_units ),
'Dense4': hp.choice('Dense4', hidden_units ),
'Dense5': hp.choice('Dense5', hidden_units ),
'Dense6': hp.choice('Dense6', hidden_units ),
'Activation1': hp.choice('Activation1', activation ),
'Activation2': hp.choice('Activation2', activation ),
'Dropout1': hp.uniform('Dropout1', 0, 1),
'Dropout2': hp.uniform('Dropout2', 0, 1),
'Dropout3': hp.uniform('Dropout3', 0, 1),
'Dropout4': hp.uniform('Dropout4', 0, 1),
'Dropout5': hp.uniform('Dropout5', 0, 1),
'Dropout6': hp.uniform('Dropout6', 0, 1),
'hidden_layers': hp.choice('hidden_layers', hlayers),
'Optimizer': hp.choice('Optimizer', optimizer),
'learning_rate': hp.choice('learning_rate', lr),
'epochs': hp.choice('epochs' , epochs),
'batch_size': hp.choice('batch_size' , batch_size)
}Defining the objective function
def Optimization(space):
### Define your model here
model.compile(loss='categorical_crossentropy',metrics='accuracy'],
optimizer=optim)model.fit(train_data, train_label,
batch_size = space['batch_size'],
epochs=space['epochs'], validation_split = 0.2)score, acc = model.evaluate(x_test, y_test, verbose=1)return {'loss': -acc, 'status': STATUS_OK, 'model': model}
The same fmin method is used to find the best possible hyperparameters.
Genetic Algorithm
Defining the search space
search_space = {'hidden_layer_sizes': hidden_layer_sizes,
'activation': activation,'solver': optimizer,
'learning_rate_init': lr, 'batch_size' : batch_size
}Using the same TPOT classifier, we can implement the genetic algorithm on deep neural network architecture.
Observations/ Results
- Parallelism Capabilities: In bayesian optimization, the experiment in the current step depends on the information from the previous experiment because it needs to update the posterior once the additional data is added using the acquisition function and the surrogate model. Whereas in the genetic algorithm, multiple samples can be trained parallelly, and their evaluations could be used to select the best set of solutions. There is a concept called parallel genetic algorithm where multiple genetic algorithms will execute to solve a single task, and the best solution will be selected from each algorithm. Then these best solutions will be evaluated with each other, and the best among them is selected for training the model. This approach is also known as the ‘island model.’ Bayesian Optimization cannot exploit the parallelism, but genetic algorithm makes good use of parallelism.
- Computational Resources: To run any machine learning algorithm, we require computational resources. In Bayesian Optimization, it does not require a lot of computational resources compared to the genetic algorithm. In the genetic algorithm, to go from one generation to the next, it needs to train the same model on multiple hyperparameters. In contrast, Bayesian optimization is used to train a single model and update the posterior information, which does not require many computational resources. A genetic algorithm should be applied when there are enough computational resources; otherwise, it would be infeasible.
- Memory Requirement: Both the hyperparameter search techniques can solve complex optimization problems. But when the individual solutions become large, for example, in deep neural network architecture, the number of hyperparameters is more, then to store all the information about the multiple individuals is not feasible. At the time of the crossover, it requires all the individuals from the previous generation. We could think to store such an amount of data onto the disk but then reading the data from the disk makes the algorithm slower. Whereas in bayesian optimization, we are not required to store such an amount of data, it requires to store only prior distributions, and the posterior is updated in each step.
- Search Space Exploration: Both the hyperparameter search techniques do not guarantee the optimal solutions for the problem. Initially, some random sets of hyperparameters are selected in the genetic algorithm, and the model is trained on these hyperparameters. The searching of the next sets of hyperparameters depends on the mutation and genetic operators. The problem is that the genetic algorithm will be stuck at the local optima and not find the global optima. Similarly, Bayesian optimization does not guarantee the optimal solution. Still, it reduces the possibility of getting stuck at local optima by using the statistical mean and variance given by the surrogate model.
- Accuracy: Initially, I have implemented both models by selecting the hyperparameters by myself. The random forest classifier gives an accuracy of 73%, and a deep neural architecture gives 79% accuracy. When I implemented Bayesian optimization on these two models, RFC gives an accuracy of 84%, whereas the deep neural network gives an accuracy of 89%. Finally, on applying the genetic algorithm, RFC gives an accuracy of 92%, and deep neural network gives ab accuracy of 94%.
- Time Complexity: The time complexity of the genetic algorithm is O(gnm), where g is the number observation, n is the number of individuals at each generation, and m is the size of the individuals. So, the time complexity of the genetic algorithm is directly proportional to the population and its size. Whereas in Bayesian optimization, the time complexity id O(n^2d^2) where n is the number of samples on which the surrogate function is evaluated till now and d is the number of hyperparameters. So the time taken by bayesian optimization increases as the samples are added to the data.
Conclusion:
Both the hyperparameter search techniques have their pros and cons. The genetic algorithm does not require any probabilistic model and directly works with the objective function. It has excellent parallelism capabilities. The genetic algorithm works very well when a solution is stored in the memory, and it will make it better over time. At the same time, it will require a lot of computational and memory resources. The Bayesian optimization mimics the objective function as the surrogate model by which it takes less time on the evaluation. It takes fewer experiments to reach a better value. But it is not able to exploit the parallelism because each experiment depends on the previous experiment.
The genetic algorithm should be used when the fitness used for the selections of the candidate solutions serves the purpose of optimization that we need. Also, evaluating the fitness function should be computationally feasible because, at every generation, the fitness value is calculated for all the individuals. The genetic algorithm works very well when we have some prior information about the global optimum solution. It will make the solution better every time. We could also use the parallel genetic algorithm to search for more hyperparameter space simultaneously.
The Bayesian optimization is used when the objective function is computationally infeasible and making a probabilistic model is easy. When the configuration space is large, then it tries to search as much space as possible and gives better results in fewer experiments. Also, when there is a constraint on the computational resources, Bayesian optimization is a good approach.
Click here to go to the GitHub repository for the implementation
References
Jasper Snoek, Hugo Larochelle, Ryan P. Adams, Practical Bayesian Optimization of Machine Learning Algorithms, 2012.
David Orive, Gorka Sorrosal, Cruz E. Borges, Cristina Martin, Ainhoa Alonso-Vicario, Evolutionary Algorithms for Hyperparameter Tuning on Neural Networks Models.
Laurits Tania, Diana Randb, Christian Veelkenc, Mario Kadastik, Evolutionary algorithms for hyperparameter optimization in machine learning application in high energy physics.
Naoki Mori, Masayuki Takeda, Keinosuke Matsumoto, A Comparison Study between Genetic Algorithms and Bayesian Optimize Algorithms by Novel Indices
https://papers.nips.cc/paper/2011/file/86e8f7ab32cfd12577bc2619bc635690-Paper.pdf
